| LINUX Stuff
|
| Work in progress - Here you can find my recent efforts in 64 Bit ARM coding on 64 Bit LINUX
|
FracNEON_sp/dp_mt V1.0 Results (24/10/2022)
After the effort to code efficient single core Mandelbrot variants for ARMv8 it took some time to make it work for multicore and big/little cpu environment to also max out all cores. For multithreading I use the C++ PThread library. The needed atomic code is done in assembler. You can find versions using the Armv8-A atomic instruction and Armv8.2-A. The effect of those different atomic instructions is mostly only detectable at a very high core count (more than 16 cores).
For the graphical output I'm using SDL2, but you can also find non graphical versions in the folder. The computation time displayed only covers the calculation, not the graphical output, even if that's neglectable.
There are 4 different optimisation level versions each for single and for double precision.
Without any command line options set the code reads the available concurrent CPU threads first and sets up the amount of threads used (usually this seems to be the core count). Then it calibrates the timing and finally the benchmark runs for about 10 seconds.
You can specify a command line argument to play with the amount of threads and the amount how many repeats are done:
- FracNEON_sp_mt <amount of threads> <amount of repeats>
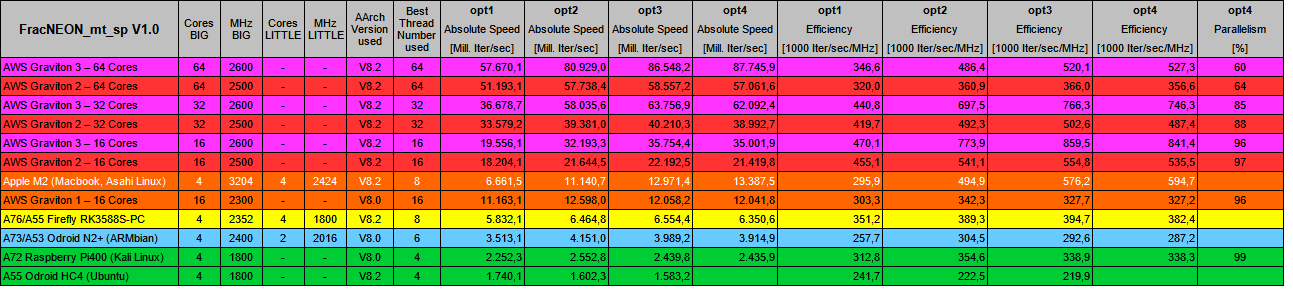
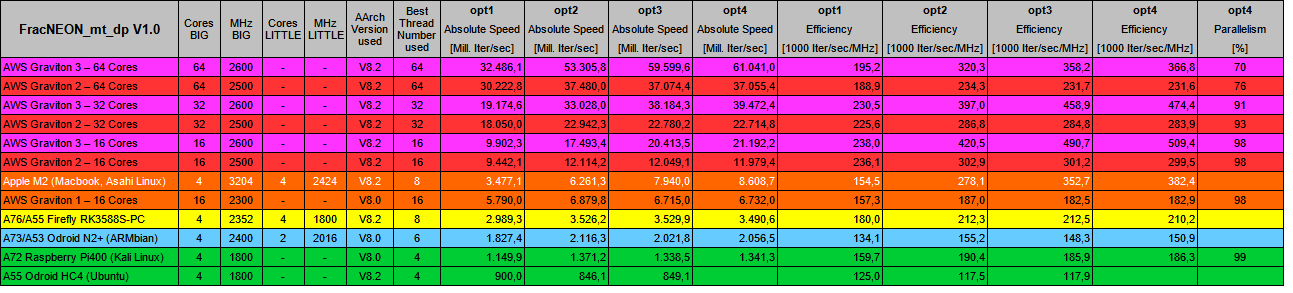
The 4 different optimisation variants calculate the exact same result regarding the Mandelbrot set but differentiate heavily in the assembler implementation to max out - if available - the multiple execution ports, the out-of-order architecture and especially the out-of-order windows of modern ARM cores. In this code I use the NEON extension in single and double precision. A brief description of the 4 variants:
- opt1 - 1 instruction block, loop unrolling 3 times
- opt2 - 2 independent instructions blocks, loop unrolling 1 time
- opt3 - 3 independent instructions blocks, loop unrolling 1 time
- opt4 - 4 independent instructions blocks within the Mandelbrot data registers, loop unrolling 1 time
To max out speed on all cores the multithreading code assigns one Mandelbrot set line at a time to each available core. If one line of any core is finished it increments the global line counter and the next available one is chosen until the set is complete. This ensures that no core ever runs idle as each line might take a different time to calculate due to the iterative nature and especially in big/little cores. So the parallelisation is still very high until higher cores counts.
If you got any questions about it just contact me. It's also my first Linux application, so there might be better ways to code the C++ part or the SDL2 implementation. And also in the assembler code I might have missed some possible speed ups. Benchmark results in table and graph:
| Download
|

|
|
|
FracNEON_sp_opt V1.0 Results
Here you will find the single task single precision results to show of the single core evolution of different CPU generations. The description of the 4 versions is the same as for the multihreading approach above. Benchmark results in table and graph:
|
|
|
|
|
FracNEON_dp_opt V1.0 Results
Here you will find the single task double precision results to show of the single core evolution of different CPU generations. Due to double precision it can only use 2 floats in one NEON register compared to the 4 floats in single precision, achieving more or less half the speed. Benchmark results in table and graph:
|
|
|
|
|
|